
由于疫情的缘故,GeForce RTX 30系列发布会被改在了黄仁勋家的厨房,但不能改变全球男孩子一夜之间为其疯狂。首发的三款产品包括了GeForce RTX 3090、GeForce RTX 3080和GeForce RTX 3070,基于安培Ampere架构以及三星8nm工艺优化而来,再实际测试解禁之前,参数上的变化就足以让人激动,曾经的消费卡皇GeForce RTX 2080 Ti甚至被甩开了数条街。


相对GeForce RTX 2080 Ti的图灵Turing架构,GeForce RTX 3090的安培Ampere架构究竟带来了什么样的改变?英伟达是如何针对游戏、光线追踪、响应乃至读写调教了这颗GA102核心?在测试解禁和白皮书放出之前,我们有幸参加了NVIDIA的架构解析会,这里不妨先从芯片架构入手,走马看花的了解一下这块能让男孩子们都哭了的芯片。

GA102:会游戏的安培
GeForce RTX 3090性能的明显提升首先源自于这块Ampere GA102核心。在硬件上GA102进行了几项更新,其中最大的改变是在三星8nm工艺定制版本下,晶体管尺寸得到大幅缩小,使得GA102装下更多内容。从整体而言,三星8nm并非时下热门的EUV工艺,而是从10nm改进而来,但得益于三星8nm定制版本的高产量和低成本,才使得GeForce RTX 30系列定价更有亲和力。
这并非NVIDIA第一次定制工艺,图灵Turing架构的12nm FFN本身就是台积电16nm工艺的优化版本,两者之间晶体管密度相同。同样三星8nm定制与三星10nm工艺之间也不会有太大区别,但相对台积电16nm而言,那提升就相当明显了,高达627mm²的芯片尺寸内融入了280亿个晶体管,这使得CUDA的数量成倍增加。

其实稍微了解一点硬件的同学都清楚,如果抛开光线追踪、深度学习超采样DLSS加速内核优化手段,图灵Turing和帕斯卡Pascal的运算性能没有疯狂增加。但安培Ampere不同,在光刻工艺升级之后,因为更多的晶体管数量,即使结构上没有做出太多重大改变,提升相当明显的。
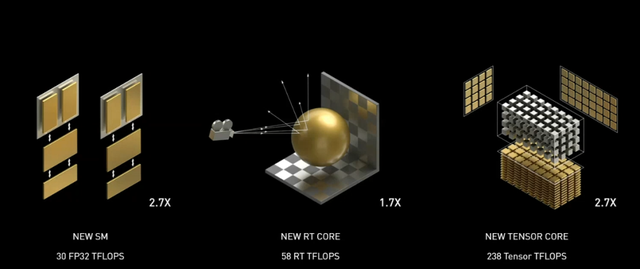
是的,加量是安培Ampere的主题,即便对比Volta,GA102也没有引入RT Core、Tensor Core的全新模块,而是对其功能、大小、数量进行了调整,NVIDIA将其称为第二代RT Core以及第三代Tensor Core。从结论上来看,安培Ampere单个SM就能比图灵Turing SM提供两倍以上数据吞吐的Tensor-TFLOPS。

回到架构本身,GA102相对今年春天发布的NVIDIA A100上的GA100增加了图形功能,但本质上Ampere架构体系不变。NVIDIA重新优化了GA102的计算单元分配,在图灵Turing的基础上引入了新的数据通道、1倍的FP32浮点运算单元,单个SM周期可以完成128次FMA操作,或者256次浮点运算。
更具体的说,在图灵Turing SM中原本用于整数运算的INT32单元变成了FP32 + INT32运算单元,根据需求不同,单元会在FP32和INT32之间切换,这使得FP32单元在使用时成倍增加。
而INT32数量变成FP32的一半其实更符合新游戏对浮点运算的要求,单元之间兼职切换也司空见惯,例如图灵Turing上的INT32就是由浮点运算单元模拟实现的,而《孤岛危机5》中的水面模拟使用精度更低的FP16则是由Tensor Core模拟实现的。
除此之外,L1数据带和纹理高速缓存带宽提升了一倍,容量提升了33%,达到了128KB。

此外加速内核中,第二代RT Core提升2倍三角形求交速度,第三代Tensor Core支持稀疏化矩阵加速,支持2倍的颗粒度稀疏化性能。接下来我们分别对这两个内核进行展开。
第二代光线追踪:流程进化
从目前实现的技术手段来看,光线追踪通过三角形求交测试和结构化加速来实现。其中三角形求交测试是指在层层叠叠无数的三角形中,找到被生成射线击中的那些射线与场景物体交汇点,而后对交汇点进行着色计算。如果利用通用计算单元,需要成千上万个单元一起找茬,在数以万计的三角形中找到正确的那数十个,然后着色。
道理是这么说,如果没有讨巧的方法,恐怕处理完一个实时光线追踪场景需要一辈子。这时候就需要引入一套加速结构算法。简单的说,如果你早餐想吃面条,那就应该走进面馆,而不是去大排档找日式料理。加速结构意思就是将有必要的东西进行分门别类,方便发出的光线能够快速准确的击中三角形。
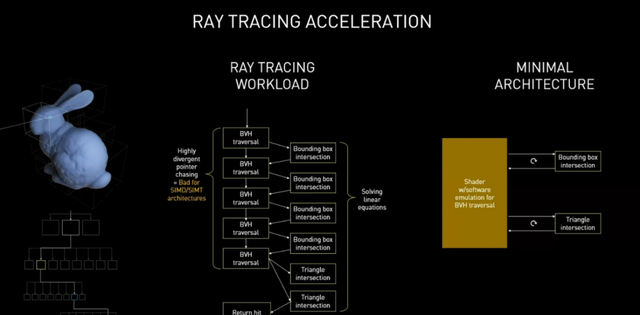
光线追踪加速结构基于1986年提出的层次化包围和BVH(Bounding Volume Hierarchy)数据结构实现。微软DXR光线追踪加速结构与BVH类似,通过两级加速结构确保射出的光线找到相应的三角形。
RT Core正是针对三角形求交测试遍历算法和BVH加速结构设计,从而也窥见NVIDIA在早期布局时已经与微软DXR不谋而合。
说白了,加速光线追踪,从DXR或者RT Core角度看来,就是层次化包围盒BVH求交加速,亦或者三角形求交加速。
在图灵Turing的RT Core每个周期中,BVH和三角形求交比重为4:1,也就是每完成4次BVH,在完成1次三角形求交,以实现三角形的命中。而在安培Ampere第二代RT Core中,NVIDIA又增加了1个三角形位置内插模块、1个三角形求交模块,也就是说,在一个周期中,完成4次BVH,在完成2次三角形求交。
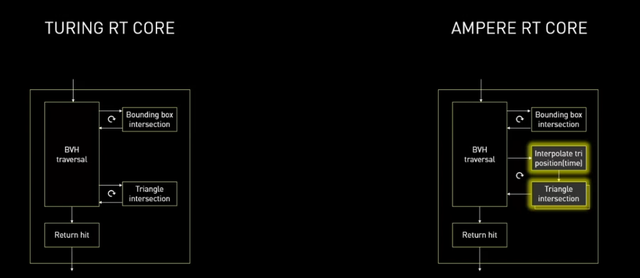
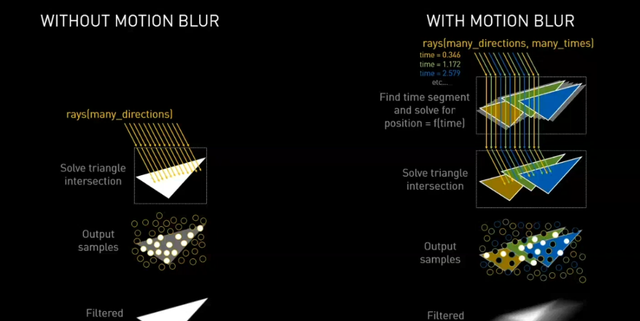
新增三角形位置内插模块,和追加三角形求交模块其实有些大胆,在一个周期的BVH遍历中照理说命中2个三角形的概率会下降。但庆幸图像画面是可预判的,特别是针对运动中的物体,2个新增的模块可以更快的实现三角形求交。特别是在启用运动模糊特效的前提下,安培Ampere RT Core性能整整提升了8倍!
第三代Tensor Core:稀疏化加速支持
如前面所言,第三代Tensor Core吞吐量提升了两倍,核心数量实际上没有增加,而是与NVIDIA A100的GA100看齐引入了稀疏化加速。在深度学习中,通过抛弃不必要的分支,在保证准确度的前提下减少运算,从而获得更高性能是可行的。
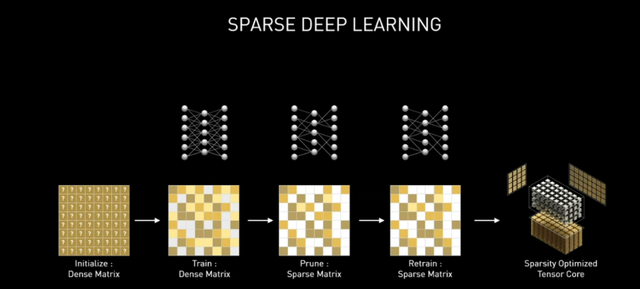
第三代Tensor Core支持细粒度模式下的50%稀疏化操作,这使得GA102的张量性能提升2倍。当然这还需要游戏和软件的支持和优化,也因为更强大的Tensor Core,GeForce RTX 3090实现了8K分辨率画面的流畅运行。
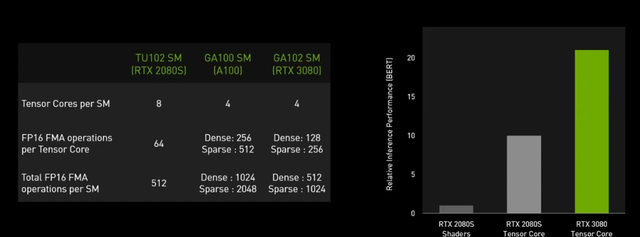
GDDR6X:美光的胜利
核心架构之外,GA102引入了新显存的支持,那就是GDDR6X。这是由美光和NVIDIA共同开发的GDDR6进阶版。GDDR6X旨在通过在内存总线上使用多级信令来实现更高的内存总线速度,并获得更大的内存带宽。
这种策略的好处美光可以继续依靠可控的成本满足NVIDIA新一代GPU对显存提出的需求,而不是将成本花在高昂的HBM2上,毕竟消费者的钱包早已饱经风霜。
GDDR6X厉害的地方在于,能够每个时钟内发出4个不同的信令,本质上是每个时钟内实现2次位移,并且分成4级电压阶跃(4种信号电平),也就是在高速网络中开始运用的PAM4信令技术。
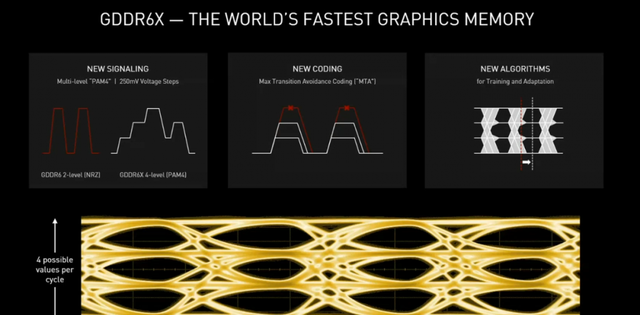
这使得原本一个信号编码只能用0和1表示,变成了如下图这般四种编码模式,即00、01、10、11。相反的,PAM4则需要更复杂的控制器来处理多信号状态。
GDDR6X也并非没有缺点,目前美光只生产8Gbit颗粒,密度与RTX 20系列相同。GeForce RTX 3080比RTX 2080多出2GB显存,是因为RTX 3080使用了320-bit内存总线,使用了10个8Gbit颗粒而非8个。因此RTX 3090想达到24GB显存,就必须使用RTX 2080 Ti两倍以上的显存颗粒。
RTX IO:GPU直读SSD
RTX 30系列除了支持PCIe 4.0之外,也引入RTX IO技术。这是一套在微软DirectStorage API基础上增加了更多压缩算法的技术。它的实现原理有点类似即将发布的Xbox Series X主机,允许GPU直连存储系统,绕过CPU完成大部分操作,实现异步传输。
值得说明的是,RTX IO虽然基于DirectStorage API衍生而来,但是在安培Ampere架构增加的算法能够让动辄上百GB的游戏有更快的加载速度。
在传统的存储协议中,硬盘数据需要通过CPU读取、压缩再传递给显卡,而RTX IO则可以通过PCIe 4.0总线实现异步读取操作。同时由于读取的是压缩数据,带宽少,从而也节约了传输资源。
这里NVIDIA用PCIe 4.0作为范例,一款读取速度能够高达7000MB/s的PCIe 4.0 SSD如果要完成数据实时解压,需要24个CPU计算资源,而RTX IO则需要半个CPU就能实现。
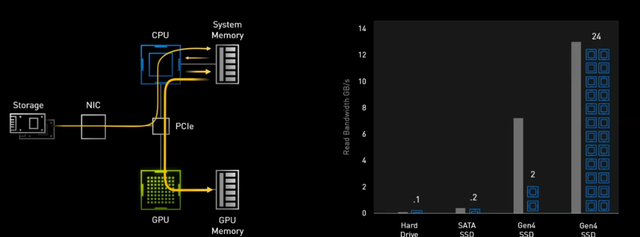
传统读盘方式效率低下
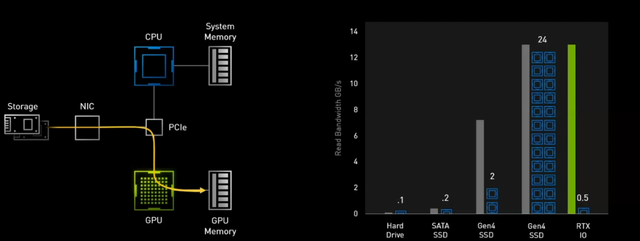
RTX IO不仅速度快,CPU占用资源少
在演示DEMO中,NVIDIA使用了Marbles作为演示范例,压缩数据搭配GPU解压,完成时间只花费了1.61秒,而未压缩数据搭配机械盘,则需要62.76秒才能完成,即使是24个CPU协同工作解压数据,也仍然需要5.02秒。RTX IO的优势高下立判。

更重要的是,DirectStorage API会在明年正式推出,相信Windows很快就会集成这个接口,如同DXR带来实时光线追踪技术一样,DirectStorage API和RTX IO给游戏带来秒读盘的意义将会非常巨大。现在这样的优势已经在即将发布的主机上开始展现了。
异形散热:突破能效
GeForce RTX 30系列拥有更多的晶体管数量的同时,使用了更高1.7GHz以上更高的频率,这使得首发的RTX 30系列显卡功耗都不低,其中GeForce RTX 3090功耗达到350W,RTX 3080也达到了320W。
NVIDIA官方表示安培Ampere的电源效率提高了1.9倍,如果按照纸面参数推论,假设GeForce RTX 3090性能提升了50%,那么功耗增加了25%,能耗效率应该增加了20%左右。
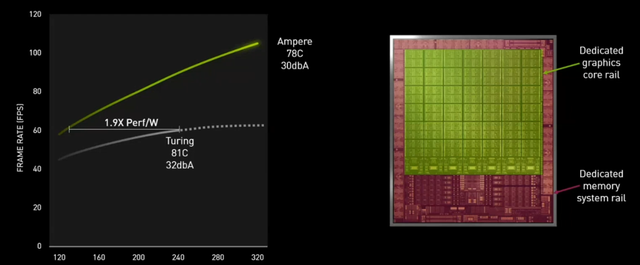
更高的频率和发热量让GeForce RTX 3090和RTX 3080在外观上带来了全面的改变。以RTX 3080为例,其PCB面积尺寸压缩到了RTX 2080 SUPER的一半,并且使用了不规则的形状,更高的元件密度势必给布线带来了更多的困难。

但这么做是有意义的。理由是NVIDIA首次在GeForce RTX 3090和RTX 3080上使用了前后双风扇系统,后方被裁减掉的PCB作用是给后方的风扇腾出向上出风的位置。形成了类似下图的机箱风道:
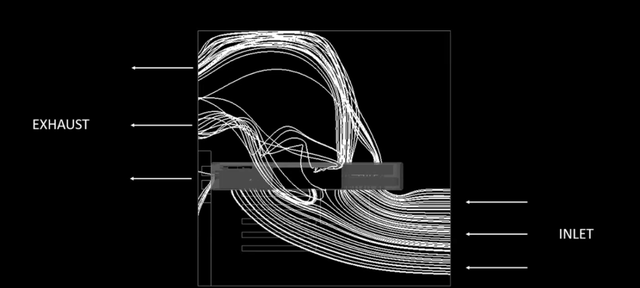
这样设计的优势也非常明显,在同等320W功率下,RTX 3080的散热和噪音均比RTX 2080更低,其中噪音降低了10分贝,温度降低了20摄氏度。值得说明的是,RTX 2080 TDP为215W,图灵Turing高功耗收益远不如安培Ampere高。
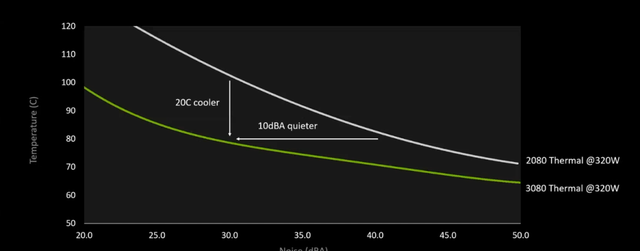
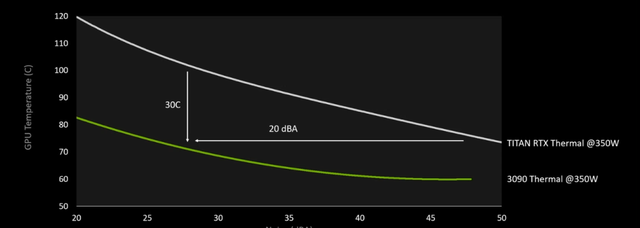
而更厉害的是,RTX 3090使用了三槽散热设计,同样是双风扇,RTX 3090相对TITAN RTX噪音降低了20分贝,温度降低了30摄氏度。
画质全面升级
功耗提升也意味着游戏性能的提升,从安培Ampere开始,显卡将原生支持HDMI 2.1输出,最高支持8K 60Hz HDR,相对4K分辨率,理论上渲染质量和帧率需要提升4倍性能。但从宣传来看,RTX 30系列能做到2倍游戏性能提升已经相当厉害,那么NVIDIA是如何做到的?

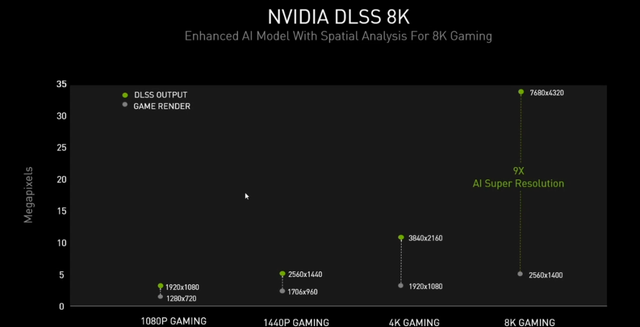
答案就是DLSS 8K。
事实上显卡只需要渲染2K,也就是2560×1440分辨率,通过AI和Tensor Core再将分辨率提升到8K。也就是说通过人工超级分辨率技术将珍格格游戏画面分辨率提升了9倍。
至于画质是否有分别,NVIDIA在分享会中也提供了DEMO作为参考,可见DLSS 8K实际效果仍旧没有让人失望。

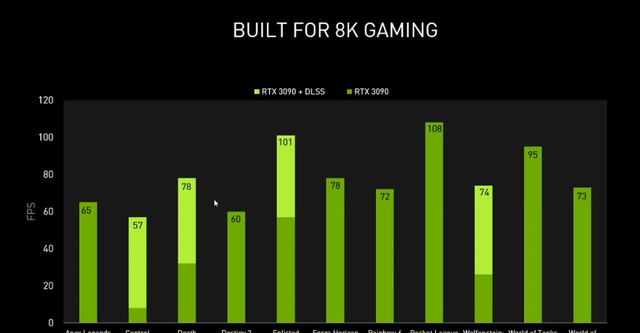
而在游戏帧率上,DLSS 8K实际运行帧数最高可以达到108FPS,平均可以达到70FPS以上。
此外,NVIDIA还针对开发人员准备了一个重头戏,叫RTXGI,也就是光线追踪版的全局光照。
全局光照目的是通过一系列算法实现场景内的逼真光照效果,包括折射、反射、满发射、阴影。也就是说开发人员尽管确定光源,剩下交给软件和GPU。
事实上RTXGI实现办法与目前许多软件的全局光照类似,通过场景设置阶段布满探头Probe,他们相当于射线反弹测试器,对各自发出的射线进行辐射和距离保存,最终用于全局光照。
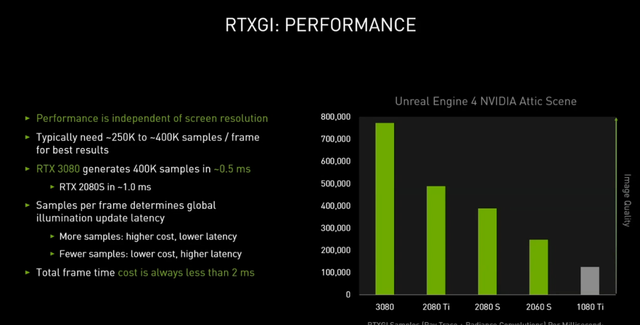
如果游戏画面需要达到光线追踪的最佳画质,单帧大概需要25万次到40万次取样。而在RTX 3080中,RTXGI可以在0.5毫秒内完成40万次取样,同时整个RTXGI过程需要的时间不会超过2毫秒。
目前这套技术已经在Unreal Engine 4.25中开始采用,这意味着游戏开发人员无需耗费大量的时间手动放置探针块,制造光线追踪场景更为容易。也从而激发更多光线追踪游戏诞生。
电竞效率提升
提升显卡性能的另外一个话题绕不过电竞,特别是第一或者第三人称射击游戏,NVIDIA一直坚定更高的帧率,更快的游戏响应时间能够换来更好的电竞成绩。NVIDIA给出了一套55ms、31ms和16ms的弹道散布图,会发现16ms弹道更为集中,那么名为NVIDIA Reflex的技术变孕育而生。
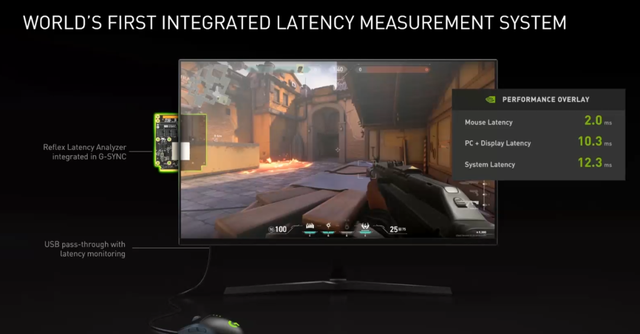
NVIDIA Reflex是一套硬件和软件结合的解决方案,它不仅包含显示器刷新率,还包括了输入输出、CPU、GPU计算、渲染列队等诸多影响。说白了,NVIDIA Reflex会在显示器上安装一个光学鼠标按键检测器,一旦发生鼠标点击,NVIDIA Reflex就会扔掉还在CPU等待渲染调用扔掉,将视野内的渲染直接发给GPU,做到即刻渲染,即刻返回显示器画面。
这意味着整套解决方案中,需要对运算力拥有更高的性能冗余,NVIDIA Reflex正式给了你玩LOL也需要购买高端电脑配置,以及更新键盘鼠标的理由。
与此同时,新版本的FrameView也集中到了GeForce Experience中,同时NVIDIA也开发了LDAT和PCAT两个套件帮助玩家进行系统延时的量化测试。
这里可以理解为NVIDIA在硬件利用上的新尝试,通过通过电竞切入点找到更多的商机乃至硬件联盟。目前包括ROG、罗技、赛睿、MSI、雷蛇、ALIENWARE在内的主流品牌已经加入到了NVIDIA Reflex阵营。
最后:硬件与软件共同进步
与许多优秀的硬件公司一样,NVIDIA已经逐步发展成硬件和软件相辅相成的解决方案公司。以安培Ampere和GeForce RTX 30系列为契机,善用性能和人工智能带来的福利,除了纯粹的游戏帧率和画质提升,无论开发者、电竞玩家、内容创作者都会获得更好的体验,GPU的普适性又向上提升了一个台阶。
不过目前的浅析仅仅是安培Ampere的冰山一角,随着未来评测和结构的解禁,我们才有机会看到看到安培Ampere在消费领域的表现和全貌。不要走开,9月中旬首发评测就会正式放出,我们拭目以待。

原创文章,作者:芒小种,如若转载,请注明出处:http://www.fhgg.net/shenghuobaike/14983.html
本文来自投稿,不代表【食趣网】立场,如若转载,请注明出处:http://www.fhgg.net/